
 Raheem Morris, whose leadership added 20.401 points to his team’s performance, was actually the best coach of the 2009 season. The worst was Brad Childress, who cost his team 10.401 points over the course of the regular season. Bill Belichick was actually slightly below average. How can we say this? I’ve developed a method of determining the contribution of a coach to his team. The exciting thing is that, as you’ll see at the end of this article, this method can be applied to any sport, not just football.
Raheem Morris, whose leadership added 20.401 points to his team’s performance, was actually the best coach of the 2009 season. The worst was Brad Childress, who cost his team 10.401 points over the course of the regular season. Bill Belichick was actually slightly below average. How can we say this? I’ve developed a method of determining the contribution of a coach to his team. The exciting thing is that, as you’ll see at the end of this article, this method can be applied to any sport, not just football.
It’s actually pretty simple, as you’ll see below. There’s a just little calculus involved, plus some matrix math, and a healthy dose of Laplace transforms. Basically, the only new principle involved is that instead of predictive power being generated by the relative measure of yards (and points), it is produced by the medial interaction of stochastic-reluctance and correlative directance. It all starts with the assumption that competitive coaching performance, of any type, is distributed according to a Gaussian distribution.
Let coaching performance be a random variable x, and let μ= its mean. Let σ= the standard deviation of coaching performance. Along the range of possible coaching outcomes, the distribution of coaching performance therefore simply becomes:
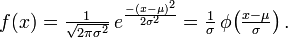
“Surplus Coach Value (SCV),” i.e. the value a coach either adds or subtracts from his team’s production can be expressed by the vector matrix Y. This vector matrix represents the yards gained above expected, given each combination of down, distance, and yard line. The values are positive for offense and negative for defense. The scalar of each vector is going to be the Pythagorean distance of the vector (r), so we get:
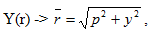
where y is the net excess yardage, and p is the sum of the team’s players individual performance. Of course, in some cases the outcome vector should be negative, which is why we’ll need to use a correction of -i (the inverse imaginary number) to maintain the property of obscurity.
Now, to get each coach’s individual contribution we’ll obviously need to use Fourier-Mellin Integral, which we’ll call X. This involves an inverse Laplace transform of the form:

where s = is a complex number of the form:
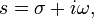
indicating the starting point of each drive and beta is the function of the stochastic fluctuation of the originating function.
Of course, we’ve ignored the risk-reward issue up to this point. For each coach H, there is a risk aversion value to describe his willingness to take chances. Based on a hyper-logarithmic utility function, we know that alpha is:
 where:
where:α = risk aversion (negative values are risk tolerant, zero is neutral)
γ = % of plays that are runs
μR = mean (expected) gain of runs
μP = mean (expected) gain of passes
σR = standard deviation of run gains
σP = standard deviation of pass gains
If we do a frequency analysis on the normal distribution using a simple Fourier transform, we can clearly see the estimate of the magnitude of Y based on the x and y values we used the vector matrix above.
I know, I know! Most of this is very simple and it’s beginning to all come together, but don’t get too far ahead. First, we need to calculate the probability of each possible outcome based on the heteroskedastic Guassian distribution (Π) as a Cartesian product of the vector matrix Y. We get:

The second term is just as simple. Since we already have strictly defined cardinality of each ordered pair in Y, all we need to do is substitute the power set of Y and multiply by the probability of each outcome. (And this goes without saying of course, we need to multiply by the imaginary correction factor –i.)
In the denominator, we need to integrate the function over infinity and multiply the result by the Laplace transform set. We get:
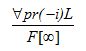
For those who don’t understand football completely, you might think that’s all we need. But there is obviously one more step. In the denominator, we need to include the play-by-play periscosities resulting from the metapolar refractive coefficient. It doesn’t matter if the play is a run or a pass, the periscosities cannot be ignored, and I think this is where previous research has erred. Previous work was based on eigenvalues of the Laplace operator, with the solution equal to:
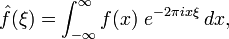
But clearly this can’t be true. For starters, extending the limits of integration to be the entire real axis would cause the unilateral or one-sided transform to be anormally extruded.
The last term simply integrates the first derivative of the surplus yardage vector matrix Y. But first, we need to use adjusted values for turnovers. In this case, I’ll use the standard 45-yard penalty for each fumble lost or interception and call it AY. This gives us:
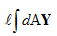
Combining each term gives us our final result, which should have been obvious all along:
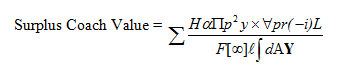







HAHAHA. Awesome!
Excellent. Who says statisticians don't have a sense of humour?
I got to "medial interaction" before I caught on ;-)
Reminds me of the dozens of sports statistical analysis papers I harvested from JSTOR.
Dude, I'm pretty sure Brad Childress is the best coach, not the worst. Are you sure you didn't miss a minus sign in there somewhere?
I don't think this is correct. You can't integrate over the adjusted turnover values as those are not continuous in every point along the curve.
Instead, I think you have to derivate over the mean estimated loss (mE). So replace the second part of the denominator with:
l*d'(mE)
and I think this makes perfect sense!
"...Let coaching performance be a random variable..."
That about covers it!
Well done.
Amazing!
love it! I actually started trying to figure out the first equation before I checked the calendar.
Any coaching ranking system that doesn't put Lovie Smith on top must be flawed, and based on an alternate reality!
Well played, sir! I actually tried to dive into this and I immediately thought, "Wow, this is a bit erudite compared to his normal work." I knew something was up when I read, "Now, to get each coach’s individual contribution we’ll obviously need to use Fourier-Mellin Integral". Obviously! Duh!
I get this same response to each of Brain's blogs.
Nice! Yes?
haha, love it!
Hilarious. Does the name 'Fourier' give anyone else the chills?
My favorite part is/are the decimals. Not only are the solutions carried out to three decimal places, they are certainly significant.
I got on this site to get a break from studying for my Corporate Finance class. This was just what I needed! If only this had come out a couple of weeks ago when I was studying for Data Analysis for Managers (aka Statistics for Future D-bags).
I ran the actual numbers for Wade Phillips and got -13.017. It works!
Brian, your best work yet.
How long did it take you to think this up?
I just started reading this today so it took me a few paragraphs before I stopped trying to figure out what you were saying. :)
Of course, this is how the majority of the sports world sees pretty much everything you post.
You beat me to the punch! I was going to make a post about that point. If we want team executives or casual fans to take our work seriously, sports researchers need to make their products clearer and use less jargon.
Yes! Less jargon,I like this stuff but sometimes get lost in the jargon.